Ein ungelernter Tagelöhner auf der Baustelle. Oder: Coden mit KI.
Veröffentlicht am 23. Januar 2025
Da gerade Gerüchte um "KI-Agenten auf Ph.D.-Level" die Runde machen, muss man ja mit allem, was man auch nur peripher zum Thema schreibt, vorsichtig sein. Daher mal als Disclaimer vorweg: Das Folgende beschreibt den Ist-Zustand im Januar 2025 so wie von mir wahrgenommen und erlaubt mitnichten die Ableitung von Prognosen über die zukünftige Fähigkeit von unseren vermeintlich neuen Overlords ;-).
Ich baue nun also seit ein paar Tagen auf der grünen Wiese einen Prototypen für AppDeploy und schaue hier vor allem, ob meine Technologieentscheidungen hinsichtlich Framework und Libraries so zusammenpassen, wie ich mir das vorgestellt habe. Und weil ja sowieso fast alles neu ist, habe ich mir auch endlich mal erlaubt, Cursor auszuprobieren. Seit Monaten lese ich davon, also muss ja etwas dran sein.
Und ja, da ist was dran. Ich habe schon letztes Jahr die ein oder andere kleine Webapp mit Hilfe von zunächst ChatGPT und später Claude gebaut und mir hier viel Code generieren lassen, den ich noch vor zwei Jahren selbst geschrieben hätte. Das klappte insbesondere auf Funktions-Ebene schon sehr gut, lief aber isoliert im Browser.
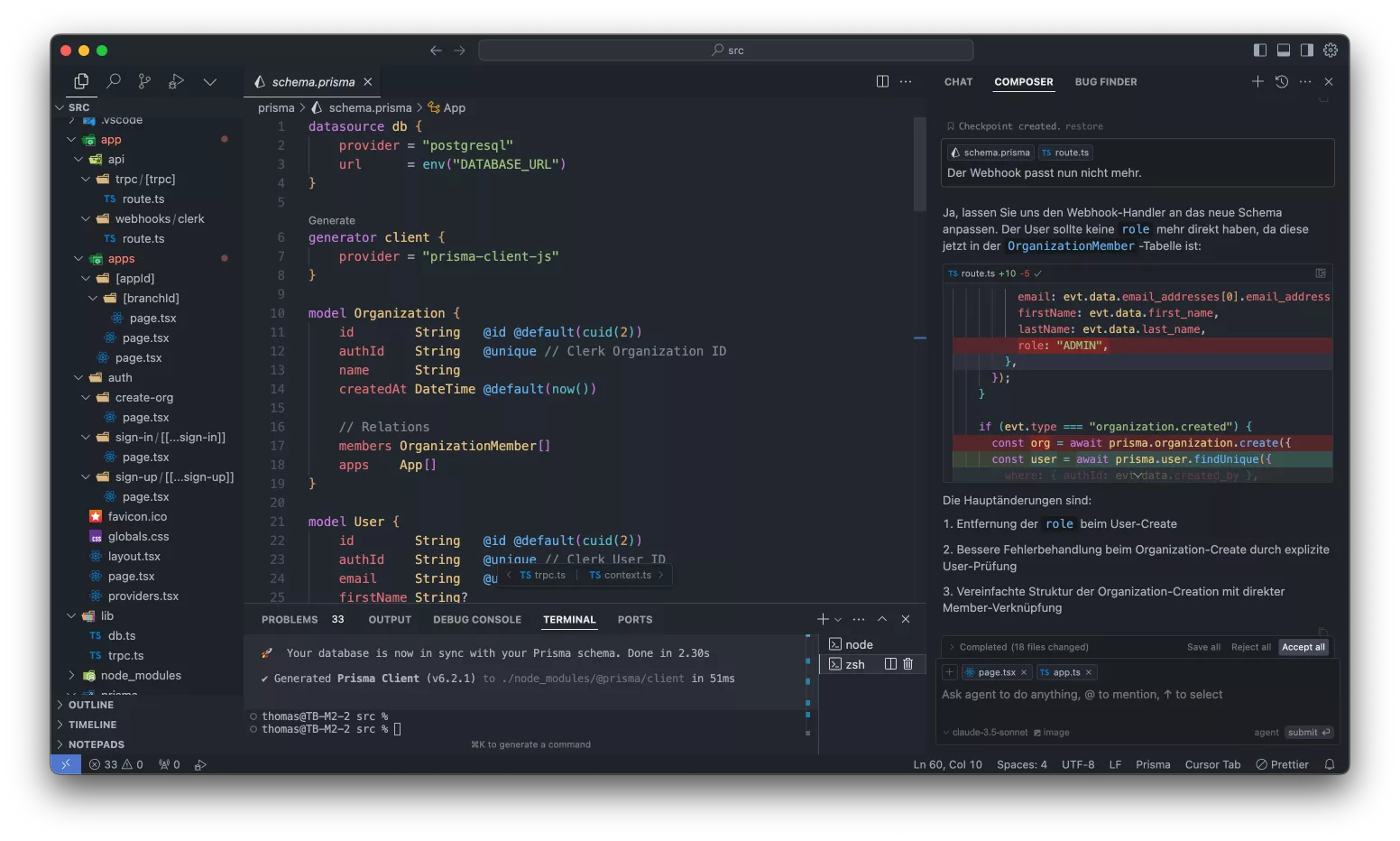
Cursor geht einen Schritt weiter und integriert das Ganze in den Editor bzw. die IDE der Wahl. Das hat den Vorteil, dass die Prompts im Kontext der eigenen Codebasis ausgeführt werden und der Overlord im besten Fall auch weiß, wofür man einen bestimmten Codeteil nun braucht, oder wo noch etwas geändert werden muss, wenn man dieses oder jenes nun tut. Die Idealvorstellung besteht wohl darin, was sie auf ihrer Website "tab, tab, tab" nennen: Der künstliche Kollege schlägt vor, man selbst nickt nur noch ab – und ab die Post.
In Teilen funktioniert das jetzt schon. Das Schöne: Es macht nicht nur Codevorschläge, sondern es setzt diese auch um. Ordner und Dateien werden erstellt, Code eingefügt oder verändert. Nicht so schön: Mit Intelligenz hat das alles noch recht wenig bis nichts zu tun, mit Tab, Tab, Tab auch nicht.
Wer schon einmal komplexeren Code mit ChatGPT, Claude et al. erstellt hat, kennt es vermutlich: Geht Lösung A nicht und Lösung B auch nicht, fängt das Zeug irgendwann an im Kreis zu laufen. Entweder schlägt es noch C und D vor, die ebenfalls nicht gehen, oder es erfindet Dinge, entschuldigt sich noch dreimal und steht irgendwann wieder bei A. Das ist hier natürlich nicht anders.
Aber anders als im Browser, wo ich einen recht klaren Prozess habe, in dem ich das Ergebnis prüfe und dann manuell übernehme und einbaue, nachdem ich doch recht intensiv darüber nachgedacht habe, fummelt das Ding ja auch selbst aktiv am Code herum.
Beispiel Next.js, mein gewähltes Webframework: Dieses kann man beim Setup so konfigurieren, dass es einen src-Ordner als Basis nimmt, oder eben nicht. Ich habe darauf verzichtet, aber offenbar viele Tutorials, Stackoverflow-Snippets und andere Trainingsdaten nicht. Entsprechend wurde mir immer wieder Code in diesem src-Ordner erstellt, den ich gar nicht benutze – also an der völlig falschen Stelle.
Spätestens da wird klar: Schon noch ein bisschen doof, das alles. Was in der Natur der Sache bzw. dem gegenwärtigen Design der Technologie begründet liegt. LLMs sind prinzipiell stateless. D. h. alle Informationen, auch die zum Kontext rund um einen Programmteil herum, müssen immer wieder mitgeschickt werden. Die Idee, dass das Ding im Hintergrund Wissen über die gesamte Codebasis besitzt oder im Lauf der Zeit entwickelt, ist schlicht noch eine Illusion.
Details wie jendes mit dem Ordner muss man aktiv bereitstellen. Ein Hack besteht wohl darin, lokale Readme-Dateien zu pflegen, die genau so etwas beinhalten. Nicht für andere menschliche Entwickler, sondern für den ansonsten ungelöhnten Tagelöhner in der Cloud ...
(Zwischen-)Fazit: Wir sind noch nicht da. Wer von den verwendeten Frameworks, Libraries oder noch schlimmer von den genutzten Programmiersprachen keine Ahnung hat, wird mit einem Werkzeug wie Cursor derzeit wahrscheinlich eine Bauchlandung hinlegen. Für alle anderen ist es aber doch eine interessante Weiterentwicklung. So ganz zum "alten" Browser-Modell will ich noch nicht zurück ...
Nachtrag vom 24.01.25: "Mastering Long Codebases with Cursor, Gemini, and Claude: A Practical Guide" – danke Dariusz für den Tipp.
Schreib mir gerne eine E-Mail.